ECC(Elliptic Curves Cryptography) 属于非对称加密算法的一个重要组成部分。
本文尽量简单地阐述椭圆曲线加密的原理,但需要读者有一些初级的数论与离散数学相关的知识,或者推荐简单地阅读《算法导论》第31章:数论算法。
椭圆曲线
首先需要明确的是,我们讨论的是什么样的曲线。
椭圆曲线有比较复杂的定义: https://en.wikipedia.org/wiki/Elliptic_curve .而我们讨论的椭圆曲线比这个简单,它是以下方程所描述的一条 平滑曲线 :
y2=x3+ax+b,4a3+27b2=0
它描述的并不是一个椭圆,之所以称它为"椭圆曲线方程", 是因为它源自于求椭圆弧长的椭圆积分的反函数。椭圆曲线是无奇点的,即没有尖点,且不会自相交。当 a,b 的值不同时,椭圆曲线会表现出不同的形态:
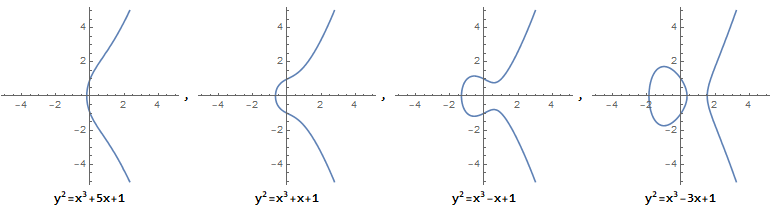
而当 4a3+27b2=0 时, 它不是椭圆曲线:
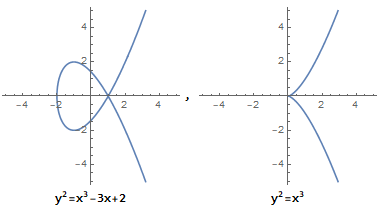
从图中可以看到,椭圆曲线总是 沿 x 轴对称 的。这是因为 y2 的存在。特殊地,我们规定 无穷远点 也存在于椭圆曲线上。我们用 0 或符号 O 来表示无穷远点,则椭圆曲线在实数域上的定义如下:
{(x,y)∈R2∣y2=x3+ax+b,4a3+27b2=0}∪{0}