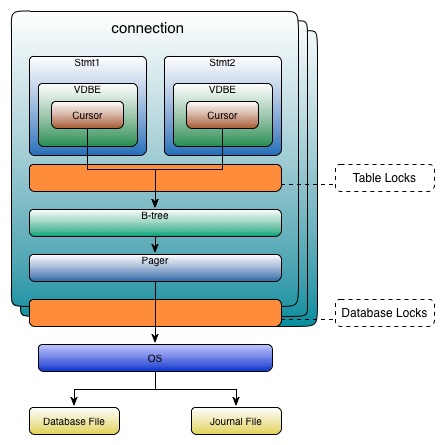
 当我们使用 GDAL 从栅格数据(RasterData)影像中读写数据的时候,我们最常使用的方法就是 RasterIO。 GDAL 在 GDALDataset 类和 GDALRasterBand 类中都提供了 RasterIO 方法。在这两个类中,RasterIO 函数的差别不大。下面我们通过一个实例来具体了解如何使用 RasterIO
当我们使用 GDAL 从栅格数据(RasterData)影像中读写数据的时候,我们最常使用的方法就是 RasterIO。 GDAL 在 GDALDataset 类和 GDALRasterBand 类中都提供了 RasterIO 方法。在这两个类中,RasterIO 函数的差别不大。下面我们通过一个实例来具体了解如何使用 RasterIO
原型
在 GDALDataset 中,RasterIO 方法的定义如下:
|
|
CPLErr GDALDataset::RasterIO(GDALRWFlag eRWFlag, int nXOff, int nYOff, int nXSize, int nYSize, void * pData, int nBufXSize, int nBufYSize, GDALDataType eBufType, int nBandCount, int * panBandMap, int nPixelSpace, int nLineSpace, int nBandSpace ) |
下面我们来了解各个参数的意义:
eRWFlag
它用来指示 RasterIO 的操作方式,读,还是写。GDALRWFlag 枚举有两个值, GF_Read = 0 为读取数据, GF_Write = 1 为写数据。
nXOff,nYOff
它用来指示 RasterIO 在影像上操作(读或写)范围的起始坐标。在影像中,左上角的坐标为 (0,0)。
nXSize,nYSize
它用来指示 RasterIO 在影像上操作范围的大小。nXSize为宽,nYSize为高。 它以 (nXOff,nYOff)为起点,决定了操作影像的范围的大小。
pData
这是一个指针,指向缓存数据块。如果 eRWFlag 为 GF_Write,函数会将 pData 中的数据写入影像,如果为 GF_Read, 那么函数会将从影像中取得的数据写入到 pData 中。 pData 为 void* 类型,它真实的数据类型将由参数 eBufType 决定。
由于 pData 为 void* 类型,所以它的大小一般使用 字节(byte) 来作单位。它的大小需要最底满足缓冲区的大小。即 缓冲区内存块大小 = 缓冲区长 X 缓冲区宽 X 波段数 X 每波段数据元大小 。用参数来表示:
|
|
//GDALGetDataTypeSize返回数据类型所占位数,故需要除以 8 int nDataSize = nBufXSize * nBufYSize * nBandCount * GDALGetDataTypeSize(eBufType) / 8 |
nBufXSize,nBufYSize
它用来指定缓冲区的宽高。这两个参数配合 nXSize,nYSize 来实现对影像的缩放。例如,如果 nBufXSize > nXSize,即缓存区宽度比影像操作区宽度大,那么读取数据时,将得到一个在 X 方向放大的缓冲数据。反之则得到缩小的缓冲数据。
值得注意的是,在读取并缩小影像时,GDAL 将自动分析金字塔(Overviews)中数据,选取合适的金字塔层来来读取数据。所以建立合适的金字塔,对读取影像的效率的很大帮助。
eBufType
它也是一个枚举,用来指示操作的数据类型。如果它与 GDALRasterBand 的数据类型不一致,则 RasterIO 将会做类型转换。需要注意的是,将数据从较大的单位向较小的单位进行转换时,RasterIO 会将数据截取而不是比例缩小。例如从 GDT_Int16(Thirty two bit unsigned integer)转为 GDT_Byte(Eight bit unsigned integer)时,超出 255 的部分将会被直接丢弃。
nBandCount,panBandMap
nBandCount为要操作的波段数。panBandMap则为读写的波段的顺序,即我们可以先读取哪一个波段,后读取哪一个波段。它是一个 int 型数组,内容为波段编号,大小为 nBandCount。这个参数可以为 NULL,这样将默认顺序使用影像的前 nBandCount 个波段来读写。需要注意的是,波段编号是从 1 开始的。 继续阅读

 脚。
脚。